一道让人惊呼“DFS还能这么玩”的题目。给定一个由象形文字组成的图像,要求按字典序输出图中所有象形文字(输出时每个象形文字由一个给定的英文表示)。关键是通过什么方法区分这些象形文字。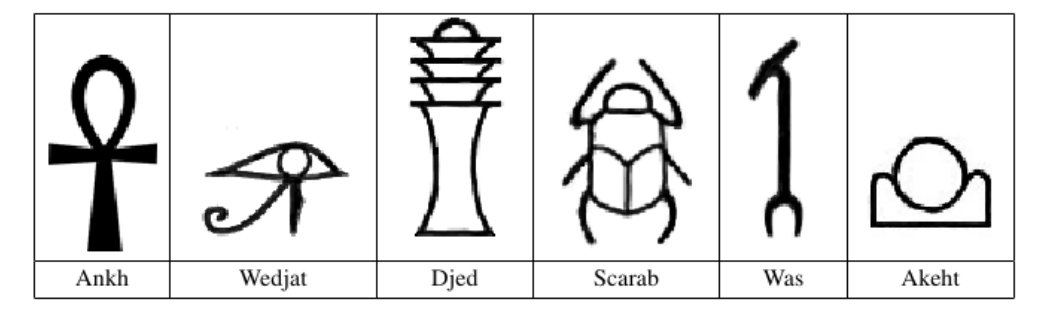
链接
题目描述
图像的像素由 $0$ 和 $1$ 组成,其中 $0$ 代表白色像素点,$1$ 代表黑色像素点。整个图像以十六进制形式给出。图像包含六种象形符号中的至少一个,不同的符号不会相互接触。符号的形状和上图给出的拓扑等价(可以随意拉伸但不能拉断)。


## 题解
需要找出能够区别出这些不同象形符号的特征量。可以发现每个符号都包含一些白色的色块区域,6个符号从左到右分别包含 $1$,$3$,$5$,$4$,$0$,$2$ 个白色区域,各不相同。所以可以根据这一特征量区分不同的象形符号。
具体做法为用dfs方法对每一块黑色或白色区域染色,这样可以把图像分为几个不同的颜色区域,再从每个黑色像素区域出发去统计在它内部的白色像素区域的个数。
需要注意的是初始时要在图像四周多添加一圈白色像素,以保证color 1 每次都表示的是背景白色像素区域(因为这个地方$WA$了好多次,$QAQ$)
另外这题没有测试数据也很坑2333,最后友情赠送几组测试数据。
代码
1 | /* |
测试数据及答案
1 | //数据 |