重温了线性代数基变换、特征值、特征向量和协方差矩阵。趁热打铁,记录一下它们在PCA中的应用。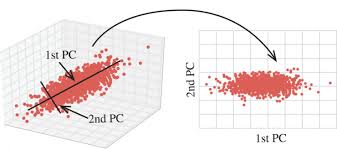
图片来源Jermmy’s Lazy Blog-PCA,到底在做什么
概念
Wikiwand:主成分分析(PCA)是一种分析、简化数据集的技术。经常用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。
简单来说,PCA可以将数据进行压缩,并且是在尽量少的丢失信息的情况下进行压缩,方便加速对数据的处理速度。
算法流程
1 | 样本数据中心化、标准化 //变量减去均值,再除以标准差 |
数据中心化和标准化是为了使得不同的特征数据具有相同的尺度
假设数据样本矩阵$D(n\times{m})$表示m个样本n维特征,则协方差矩阵$Cov(n\times{n})$,其特征向量矩阵$A(n\times{n})$,取前k维特征向量$B(n\times{k})$,那么降维后的数据:
$$
D_{PCA}(k\times{m})=B^T(k\times{n})\cdot{D(n\times{m})}
$$
PCA的意义
PCA的意义要从协方差矩阵说起,协方差矩阵表示各个变量之间的关系,包括各自变量之间的方差。将Cov在以其特征向量为基向量构成的空间中的来观察:
$$
A^{-1}CovA=
\begin{bmatrix}
\lambda_{1} & \quad & \quad & 0 \\
\quad & \lambda_{2} & \quad & \quad \\
\quad & \quad & \ddots & \quad \\
0 & \quad & \quad & \lambda_{n}
\end{bmatrix}
$$
关于为什么矩阵在以其特征向量为基向量的空间中来看是一个对角阵,且对角元素为各个特征值,可以参考3Blue1Brown的线性代数教程的9-基变换和10-特征向量和特征值。看完后会对这个变换过程有一个非常直观的理解。
上面说到协方差矩阵表示了各个变量之间和自身的关系,现在变换后的协方差矩阵除了对角线元素外,其它位置都变成0了,也就是说各个变量之间被去相关性了!在这空间下各个变量是独立的,去除了数据之间的冗余。
接下来我们选取特征值最大的前k个特征向量,由其组成新的变换矩阵B。之所以选择特征值大的,是因为特征值所在的对角位置是协方差矩阵表示方差的位置,方差越大,说明该特征变量越分散,信息量越大,压缩后越不容易恢复,所以我们保留它们而舍弃那些包含信息量小的特征变量。
最后我们只需要把样本数据投影到以提取出的k个特征向量为基向量的空间中。
如最开始的图中,在三维数据中找到两个独立的主特征,并将三维数据投影降维到了二维平面上实现数据降维。
参考
Jermmy’s Lazy Blog-PCA,到底在做什么
3Blue1Brown线性代数的本质-9-基变换
3Blue1Brown线性代数的本质-10-特征向量和特征值